Parallel NFS (pNFS) – Part 1 (Introduction)
Parallel NFS (pNFS) is a part of the NFS v4.1 standard that allows compute clients to access storage devices directly and in parallel. The pNFS architecture eliminates the scalability and performance issues associated with NFS servers deployed today. This is achieved by the separation of data and metadata, and moving the metadata server out of the data path.
Parallel NFS Introduction
High-performance data centers have been aggressively moving toward parallel technologies like clustered computing and multi-core processors. While this increased use of parallelism overcomes the vast majority of computational bottlenecks, it shifts the performance bottlenecks to the storage I/O system. To ensure that compute clusters deliver the maximum performance, storage systems must be optimized for parallelism.
Legacy Network Attached Storage (NAS) architectures based on NFS v4.0 and earlier have serious performance bottlenecks and management challenges when implemented in conjunction with large scale, high performance compute clusters.A consortium of storage industry technology leaders created a parallel NFS (pNFS) protocol as an optional extension of the NFS v4.1 standard. pNFS takes a different approach by allowing compute clients to read and write directly to the storage, eliminating filer head bottlenecks and allowing single file system capacity and performance to scale linearly.
NFS Challenges
In order to understand how pNFS works it is first necessary to understand what takes place in a typical NFS architecture when a client attempts to access a file. A traditional NFS architecture consists of a filer head placed in front of disk drives and exporting a file system via NFS.
When large numbers of clients want to access the data, or if the data set grows too large, the NFS server quickly becomes the bottleneck and significantly impacts system performance because the NFS server sits in the data path between the client computer and the physical storage devices.
NFS Performance
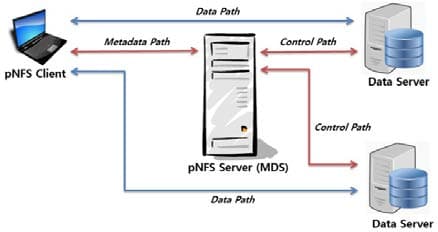
pNFS removes the performance bottleneck in traditional NAS systems by allowing the compute clients to read and write data directly and in parallel, to and from the physical storage devices. The NFS server is used only to control metadata and coordinate access, allowing incredibly fast access to very large data sets from many clients.When a client wants to access a file it first queries the metadata server which provides it with a map of where to find the data and with credentials regarding its rights to read, modify, and write the data. Once the client has those two components, it communicates directly to the storage devices when accessing the data. With traditional NFS every bit of data flows through the NFS server, with pNFS the NFS server is removed from the primary data path allowing free and fast access to data. All the advantages of NFS are maintained but bottlenecks are removed and data can be accessed in parallel allowing for very fast throughput rates; system capacity can be easily scaled without impacting overall performance.
Part 2 – Sample of pNFS Configuration
The next post about pNFS will be a post about pNFS configuration on RHEL.




So did you ever bother to finish Part 2?