I want to clear some misunderstanding in this post by some explanations about NUMA technology in physical and virtual machines.
As first step, join me to review UMA technology:
Uniform memory access (UMA) is a shared memory architecture used in parallel computers. All the processors in the UMA model share the physical memory uniformly. In a UMA architecture, access time to a memory location is independent of which processor makes the request or which memory chip contains the transferred data. Uniform memory access computer architectures are often contrasted with non-uniform memory access (NUMA) architectures. In the UMA architecture, each processor may use a private cache.
Peripherals are also shared in some fashion. The UMA model is suitable for general purpose and time sharing applications by multiple users. It can be used to speed up the execution of a single large program in time-critical applications
NUMA technology:
Non-Uniform Memory Access (NUMA) is a computer memory design used in multiprocessing, where the memory access time depends on the memory location relative to a processor. Under NUMA, a processor can access its own local memory faster than non-local memory, that is, memory local to another processor or memory shared between processors.
Now what is vNUMA?
vNUMA removes the transparency between the VM and the OS and presents the NUMA architecture directly to the VM’s operating system. It worth mentioning that vNUMA also known as wide NUMA in the industry. For a wide VM, the underlying architecture where the VM runs, the NUMA topology of the VM spans across multiple NUMA nodes. After the initial power-up of a vNUMA-enabled VM, the architecture presented to the OS is permanently defined and cannot be altered.
This restriction is generally positive because changing the vNUMA architecture could cause instabilities in the OS, but it could cause performance problems if the VM is migrated via vMotion to a hypervisor with a different NUMA architecture. It is worth mentioning that although most applications can take advantage of vNUMA, the majority of VMs are small enough to fit into a NUMA node; recent optimization on wide-VM support or vNUMA does not affect them.
Therefore, how the guest OS or its applications place processes and memory can significantly affect performance. The benefit of exposing NUMA topology to the VM can be significant by allowing the guest to make the optimal decision considering underlying NUMA architecture. By assuming that the guest OS will make the optimal decision given the exposed vNUMA topology, instead of interleaving memory among NUMA clients.
Why NUMA is important?
Multi-thread applications need to access to local memory of the CPU cores and when it has to use remote memory, performance will be impacted cause of latency. Accessing to remote memory is very slower than local memory.
So using NUMA will improve performance. Modern operating systems tries to schedule processes on NUMA nodes (Local Memory + Local CPU= NUMA node) and processes will have access to the cores with local NUMA node.
ESXi is also use NUMA technology for wide virtual machines and distributes virtual cores across multiple NUMA nodes when virtual cores are more than 8. When machine is powering up, virtual cores will be distributed to different NUMA nodes and it will improve performance because virtual cores will access to local memory.
Now there is two questions:
Is there any relation between virtual sockets and NUMA nodes?
Does number of virtual sockets impact performance?
First, I should say that there is no difference when you have assigned more virtual sockets with one virtual core or one virtual socket with more virtual cores. Virtual sockets just impact on your software license and not performance.
Our Scenario
We have two servers, HPE DL580 G8 with 15 cores per socket (120 logical cores) and HPE DL380 G8 with 10 cores per socket (40 logical cores).
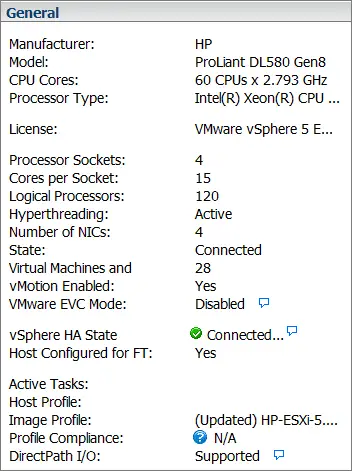{kind=link}
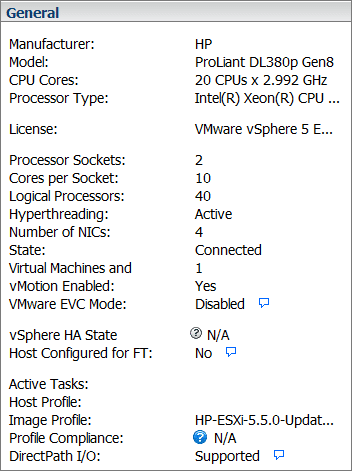{kind=link}
Now, at first step, I assign 10 sockets to a Linux virtual machine from DL380:
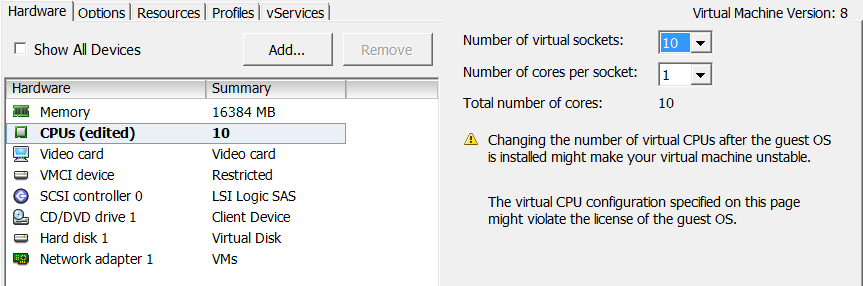{kind=link}
When I check NUMA node in the OS, OS says that I have one NUMA node and all cores are scheduled on the node:
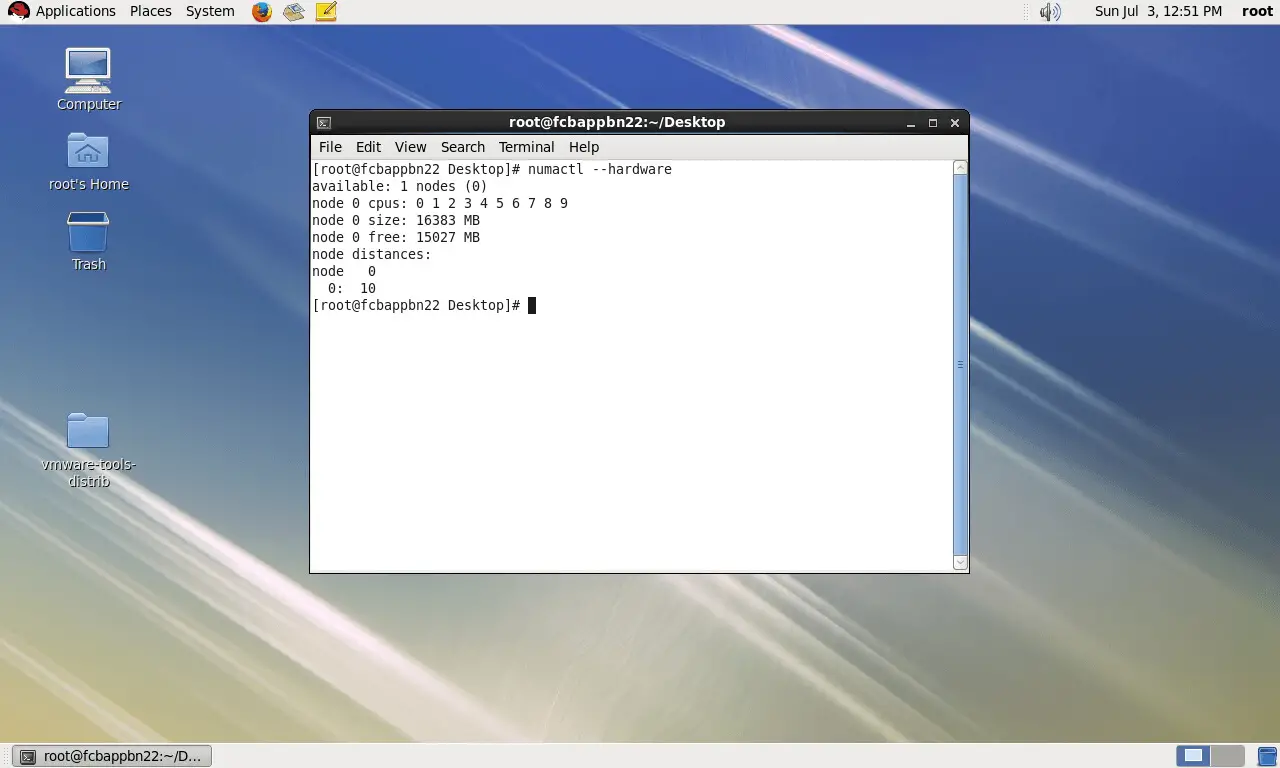{kind=link}
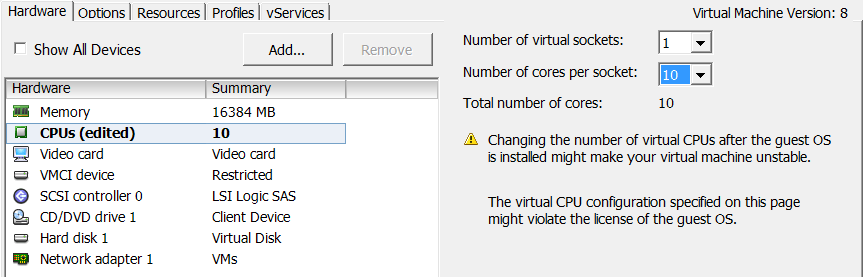
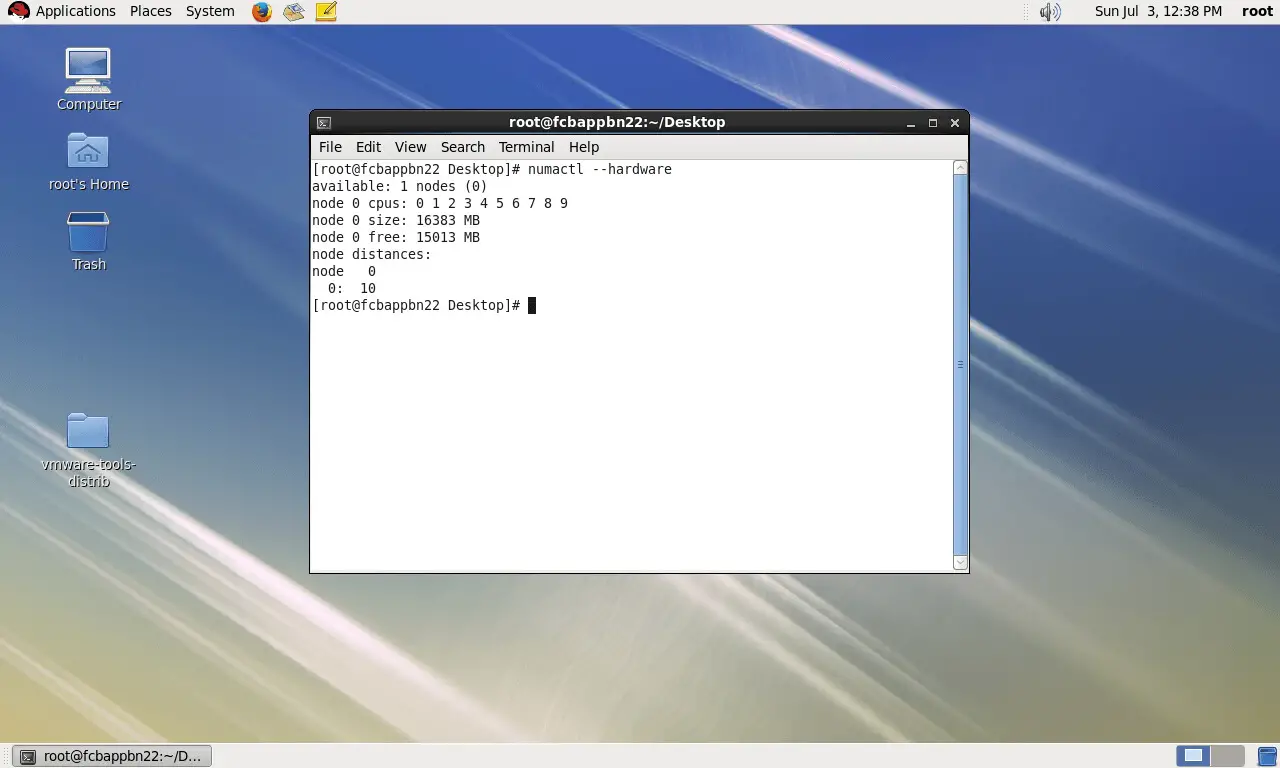
Now, I assign one socket and 10 cores to the VM, please see the result on VM:
{kind=link}
{kind=link}
We have 1 NUMA node with 10 cores and 1 socket! So it seems, there is no difference between assigning cores and sockets!
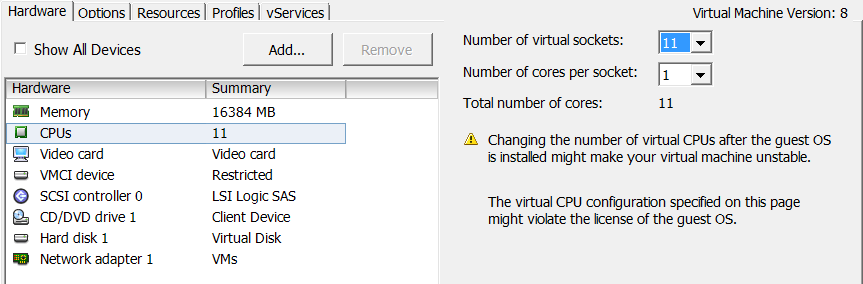
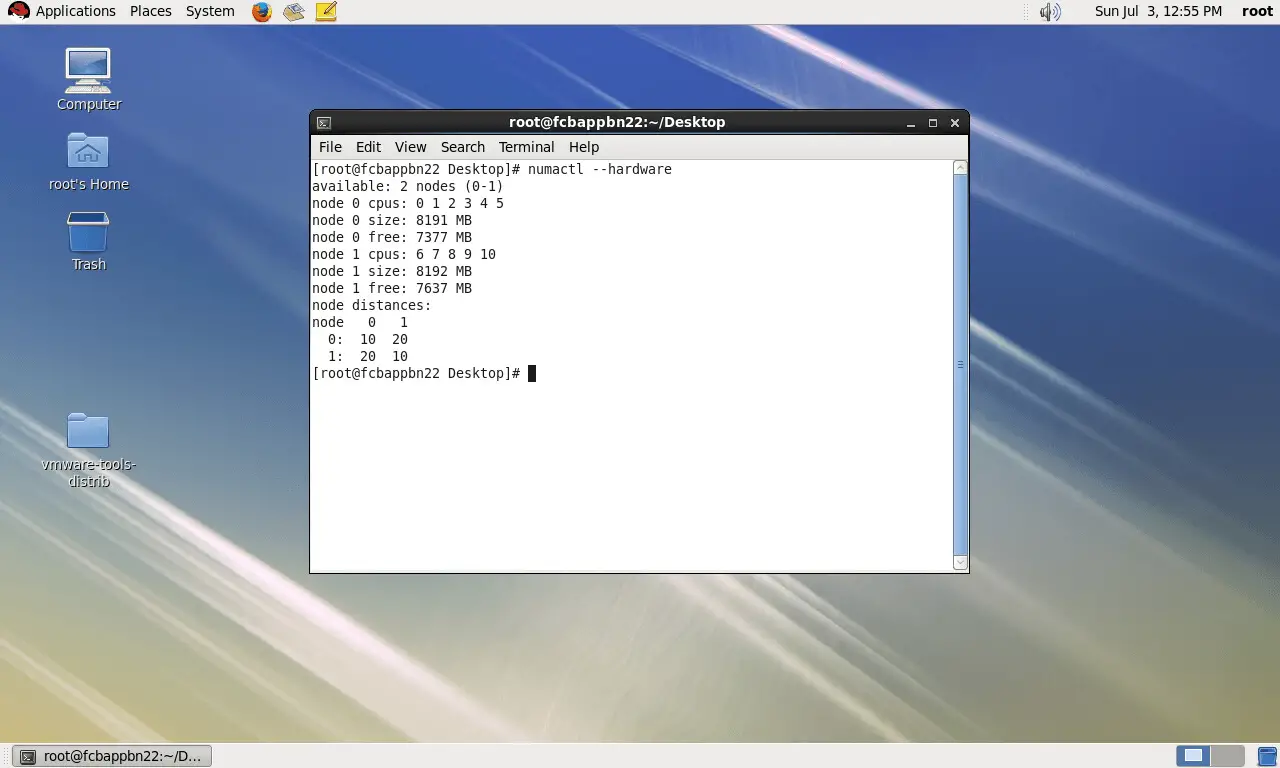
What if I assign 11 sockets to the machine?!
{kind=link}
{kind=link}
Now, we have two NUMA nodes and 6 cores are assigned to the first and 4 cores are assigned to the second!
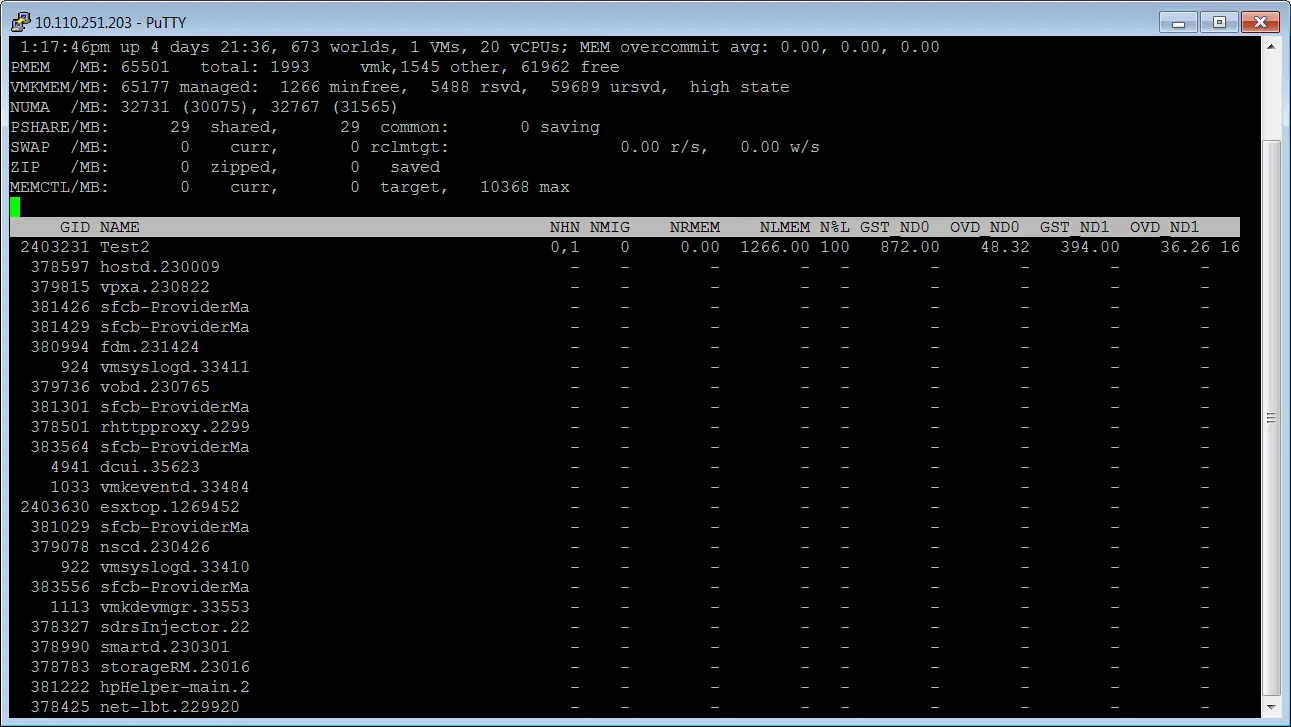
Now, what if I assign 20 sockets and 1 core per socket to the machine?
I have assigned 20 sockets to the machine and then I have checked it by ESXTOP tool.
You can see that we have two NUMA nodes, if you test the same scenario and check NUMA nodes in OS, you will see just two NUMA nodes.
This is another proof and shows that number of sockets does not matter!
{kind=link}
Till now, we have assigned cores to our machines smaller than our physical cores number, but sometimes we need to more core and we have hyper-threading on our CPU.
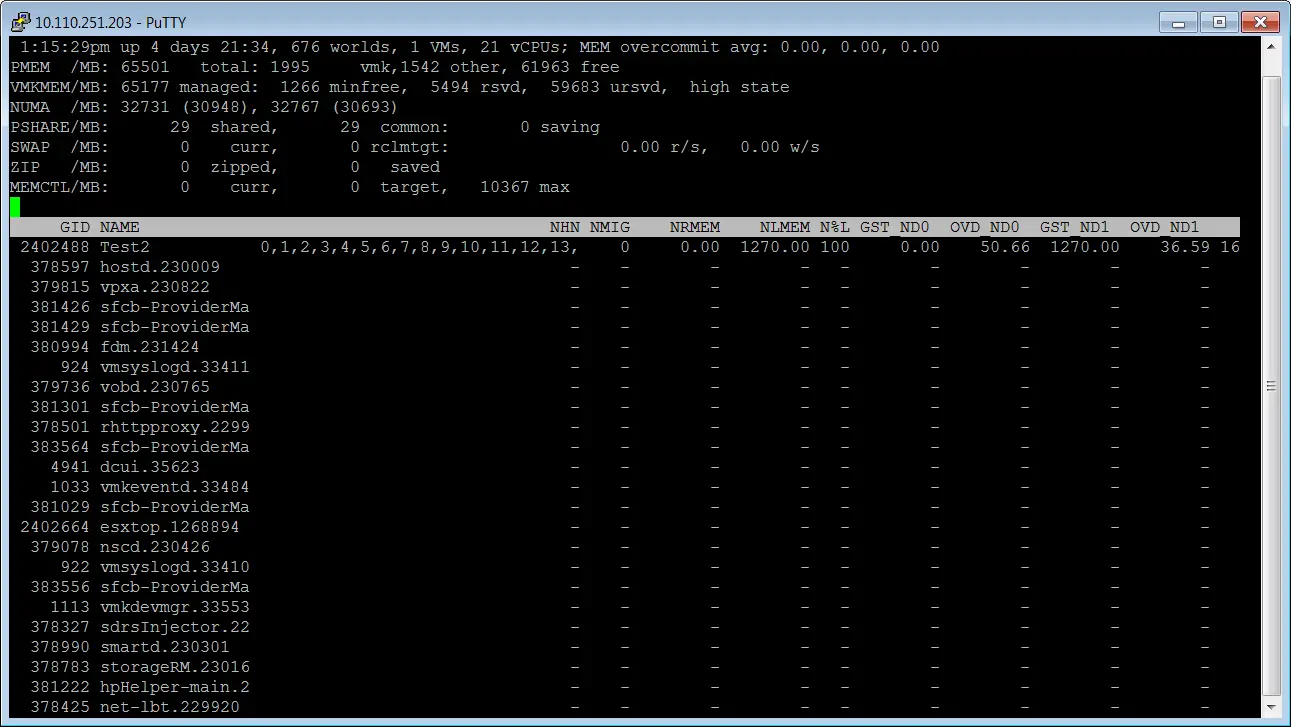
So what if I assign 21 sockets to our machine?
{kind=link}
{kind=link}
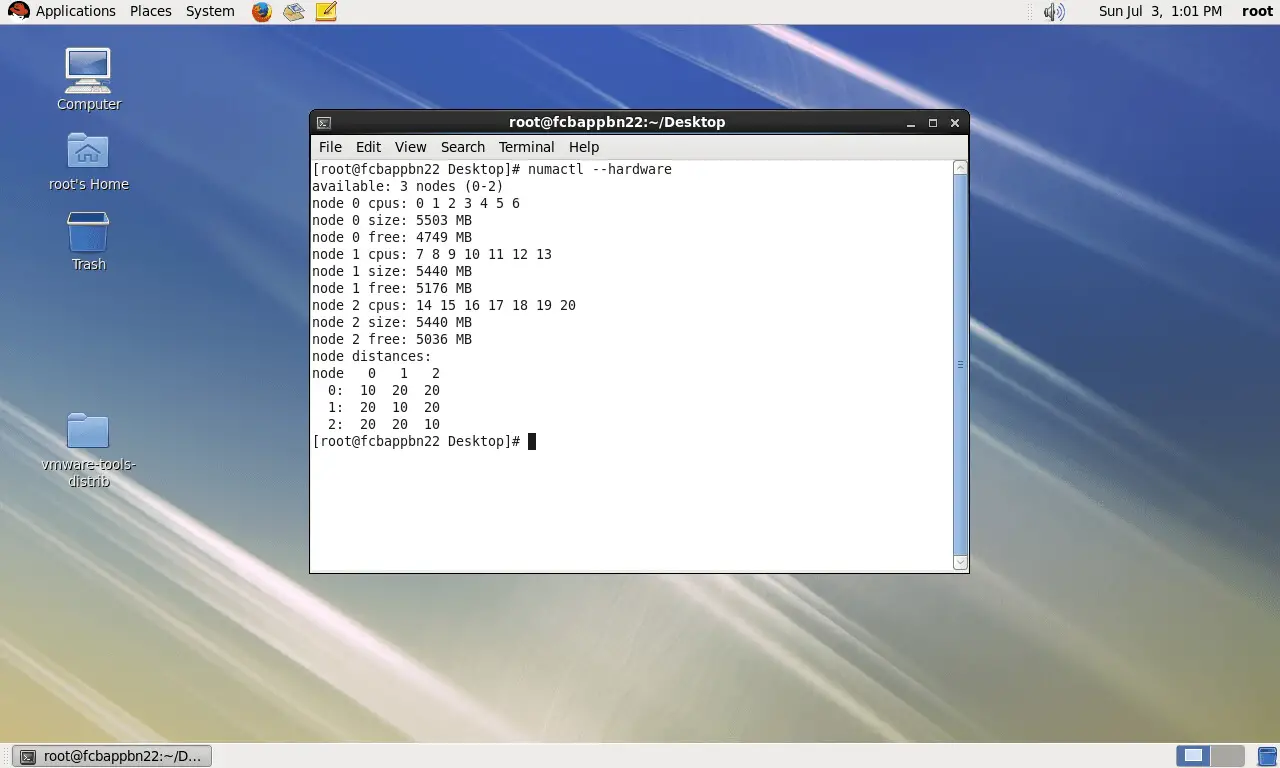
You can see that ESXi distributed the cores on 14 NUMA nodes and we should call it vNUMA node, also when I checked NUMA nodes via OS, there was 3 NUMA nodes but we have two physical NUMA nodes!
You can check this scenario with cores instead of sockets but I’m sure that the result will be same.
Now, second question:
As you have seen, there is no difference between cores and sockets, so there is no impact on performance when you assigned one socket with some cores or some sockets with one core.
Further Reading
I/O Block Size (> 3 MB) Best Practice on EMC AFA/HFA and Linux (Physical and Virtual)
HPE OneView Global Dashboard: Best Software for Global Monitoring
CPU Core Limit in Oracle Database: Best Solution for Dummies
LINBIT (DRBD, LINSTOR): One of The Best Software Defined Storage Solutions
View Comments (2)
Actually in my set up, number of virtual sockets = num of numa nodes.........cores per socket are cores per numa
VMware vSphere can handle unbalanced NUMA configuration (The post was about that). You should consider about memory size in CPU configuration as well.
Read the examples in the below link:
https://blogs.vmware.com/performance/2017/03/virtual-machine-vcpu-and-vnuma-rightsizing-rules-of-thumb.html