Linux Deduplication and Compression: The Ultimate Guide to Saving Space
Cost of storage is the biggest piece of IT budget in any company (Of course not EMC, HPE or other like them 😀 ) and the storage spaces is eating by databases, other data files and backup files as well. Lot of those data file not be used once generated!. I have serious issue with these types of data and especially log files that one of dark data types. I can’t stop generating those data and the related teams are always crying about free space on their servers. They want just Linux servers (Seems, they don’t know Windows has NFS services as well), because they are using shared space on application servers to storing log files and others via NFS.
I have offered other solutions such as using Windows as NFS server and use deduplication on Windows Servers, this feature is really good. I have used Windows deduplication on our backup proxy servers and result was incredible. Anyway, they want to Linux server (Not even other Unix-Like!), so I started to googling these:
- Linux Compression
- Linux Deduplication
- XFS Deduplication
- ………
Don’t panic, most Linux’s modern file systems have no native deduplication and transparent compression and must be enabled with third-party software. Let’s see what is deduplication and compression?
What’s Data Deduplication?
Deduplication in term refers generally to eliminating duplicate or redundant information. data deduplication is a technique for eliminating duplicate copies of repeating data.
https://en.wikipedia.org/wiki/Data_deduplication
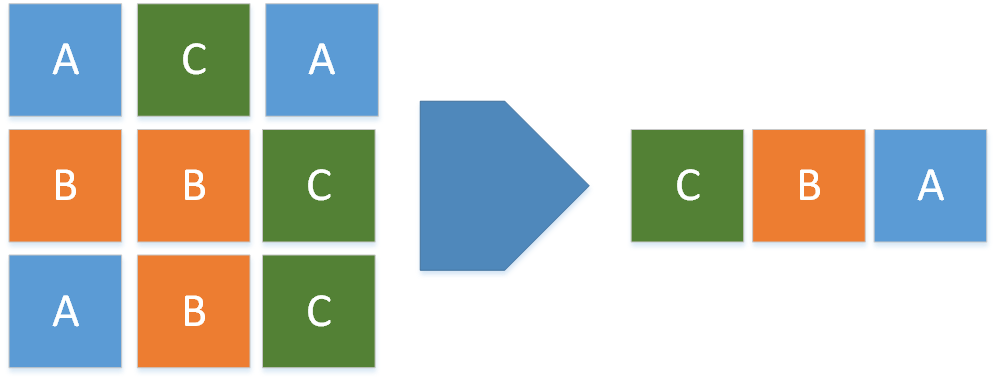
Look at the above image, it’s showing deduplication process but the real process very complicated compare to the published images with documents. Depends on operating system or anything like that, deduplication may be little different but all do same things. During the process, instead of writing the same data more than once, detects each duplicate block and records it as a reference to the original block. Multiple logical block addresses will share same physical block address.
Data Deduplication Types
Data deduplication can be during storing data which called Inline-Deduplication, also data deduplication can be done after storing which called Post-Processing Deduplication. Modern storage devices such as EMC XtremIO offering inline-deduplication on SSD or NVMe.
Inline deduplication is the best, because there is no need to have enough space for original data, original data will store as deduplicated data from beginning.
Predetermine Deduplication Ratios
You can determine deduplication ratio before processing data, of course there is some standard ratio about different data types. Pre-Compressed data such as compressed files (Zip, GZip and others), compressed media files, encrypted data, meta data will show lower deduplication ratio.
What’s Data Compression?
While deduplication is the optimal solution for virtual machine environments and backup applications, compression works very well with structured and unstructured file formats that do not typically exhibit block-level redundancy, such as log files and databases.
There are many different algorithms for compression, it might be different base on file system, operating system and anything else. Different algorithms will show different result and will need different amount of resources.
My Choices, My Tests in Linux
Recently, I’ve read about Virtual Data Optimizer (VDO) on RHEL 7.5 and above. VDO is data compression and deduplication on Linux which provided by “Permabit Technology Corporation”. Red Hat acquired Permabit in 2017, so VDO owner is Red Hat now and it will be available as kernel module in RHEL 7.5 and above. I’ve tested VDO in RHEL 7.7, results was good but not perfect also there is something strange.
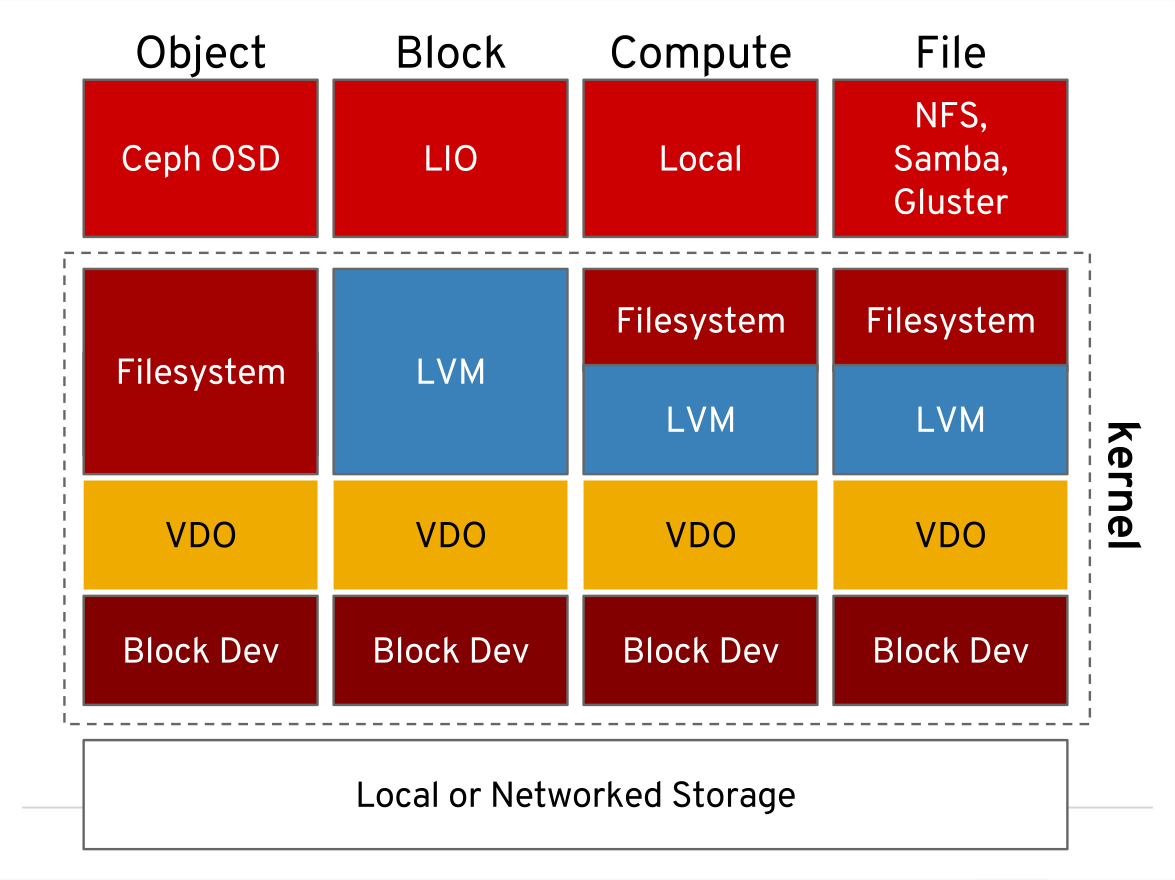
Take a look to the below image. VDO is between File system/LVM and block devices. So file system or LVM doesn’t know that how big is block device! During VDO device creation, you need to specifying VDO Logical Size, then create file system on that. If block device is 1 TB disk, you can define logical size to 10 TB. Don’t be happy, depends on data type, you can fill the drive and VDO does its best to compression and deduplication. Always VDO device should be check by “vdostats”. Because file system has no sense about block device layer. Oversubscribed block device can led you to serious data corruption.
The Tests
I had two different tests, first test was about uncompressed files such as log files. First test’s result was very good 75% space saving. Almost 7.5 TB file on 1 TB disk space.
Second test was about storing pre-compressed files and space saving was near ZERO! As I said in “Predetermine Deduplication Ratios”, pre-compressed files will not show good deduplication ratio. Also VDO didn’t detail information about compression and deduplication, just VDO shows that how much space is saved!
Actually, I didn’t test other options such as OpenDedup. But I’ve tested compression and deduplication on BSD, ZFS result was better than VDO also Windows Deduplication was much better than both.
Same as ZFS, VDO also needs large amount of memory to working with large block devices. As you can disable deduplication and compression, sometimes compression is enough on VDO and ZFS. I want test deduplication on storage devices and share the result as well in another post.
Conclusion
Most of IT engineers think that disk space is cheap but disk space can be very expensive if there is no proper plan for storing data.
Data reduction features such as deduplication and compression in different layers would be useful but it also depends to data type.
Most modern operating systems and file systems have native an non-native compression ad deduplication feature. Virtual Data Optimizer is supporting by Red Hat and it’s one of the best software in this regard. I hope, new VDO versions will come with more improvements.
Further Reading
Red Hat Enterprise Linux 8.0 Beta
How to Configure VNC Server in Red Hat Enterprise Linux 6.x/7.x
External Links
A look at VDO, the new Linux compression layer – Red Hat Blog
Understanding the Concepts Behind Virtual Data Optimizer (VDO) in RHEL 7.5 Beta – Red Hat Blog
Determining the Space Savings of Virtual Data Optimizer (VDO) in RHEL 7.5 Beta – Red Hat Blog
Introducing Virtual Data Optimizer to Reduce Cloud and On-premise Storage Costs – Red Hat Blog